Projects & Highlights
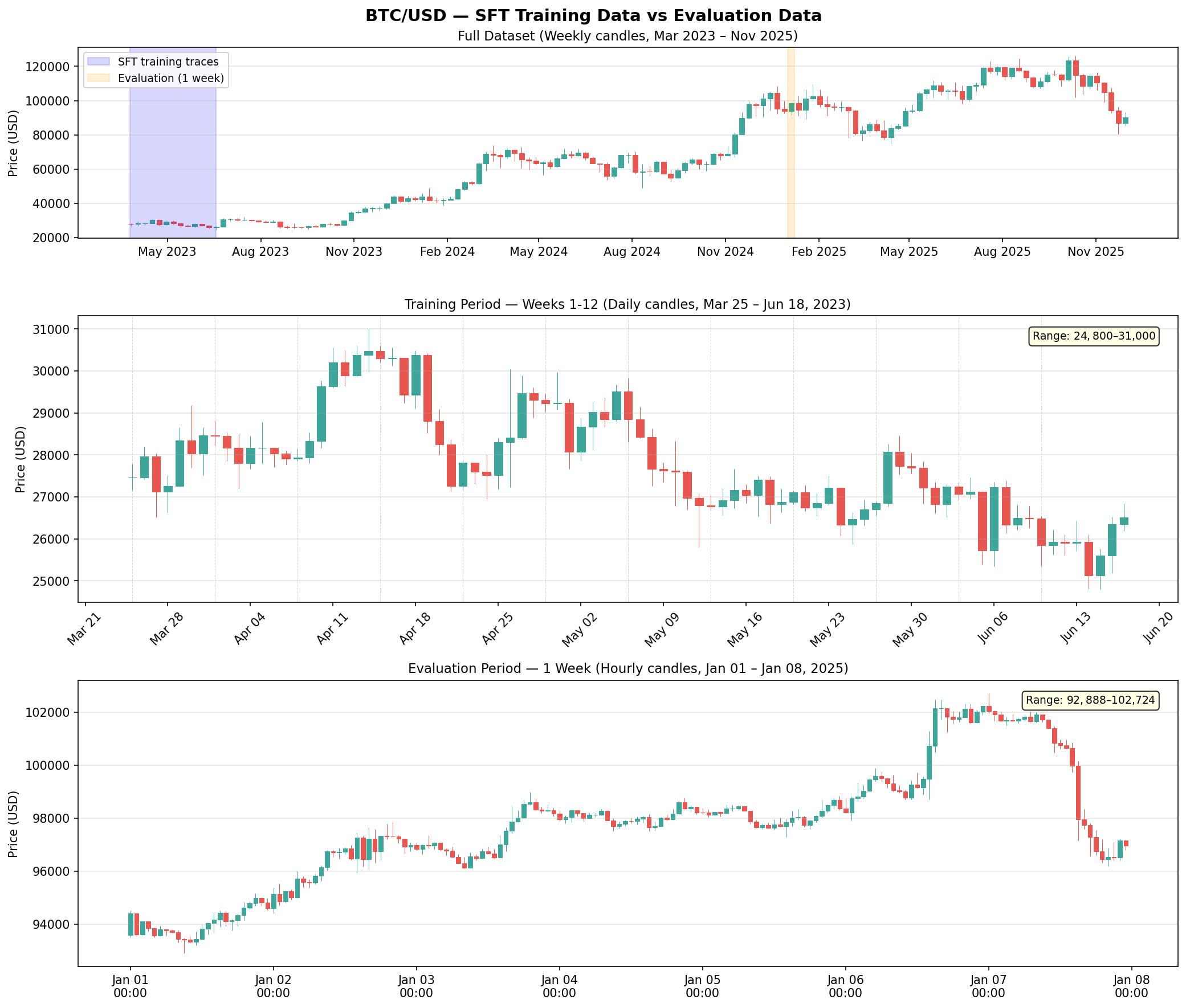
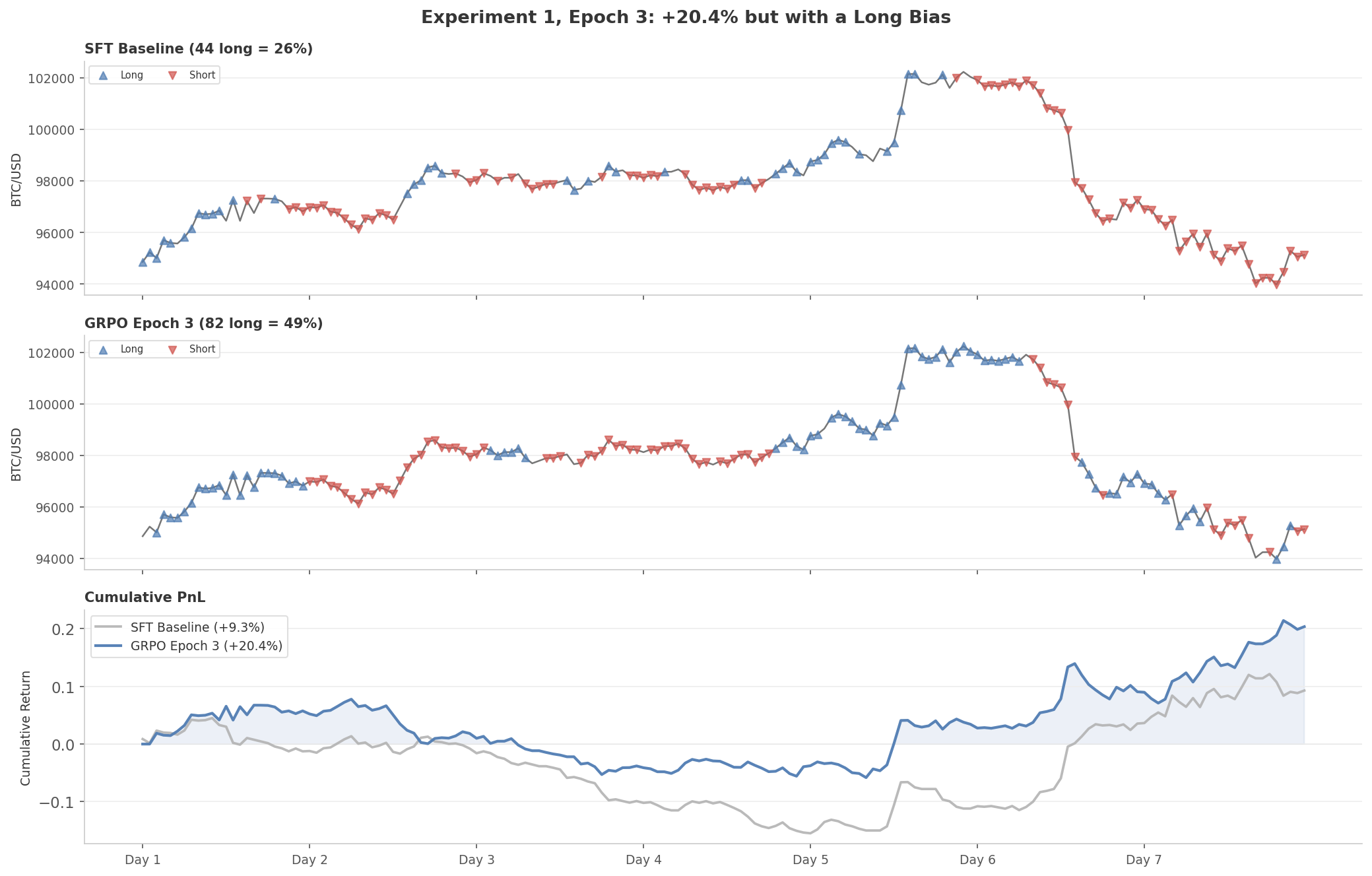
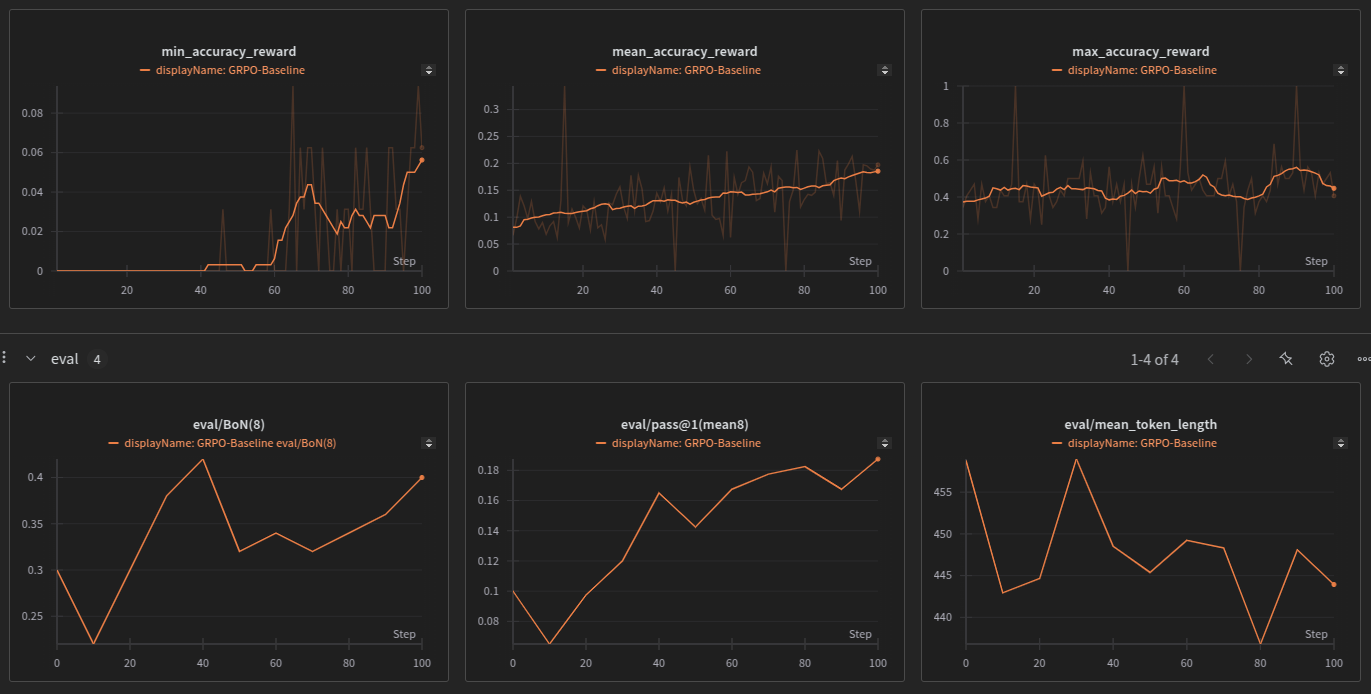
Distributed RL for LLM Fine-Tuning
Multi-GPU distributed RL framework for fast and memory-efficient LLM fine-tuning. Uses Ray for orchestration, vLLM for inference, and Unsloth for training. Supports flexible actor-to-learner GPU ratios and implements Policy Gradient and GRPO.
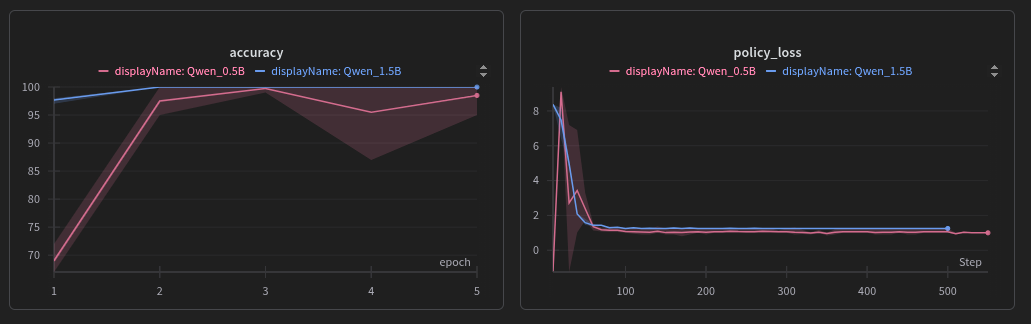
Agent Tool RL
Training small language models to use tools with RL. Even a 0.5B model goes from 12% to 100% accuracy on math tasks once trained with RL to call a calculator tool.
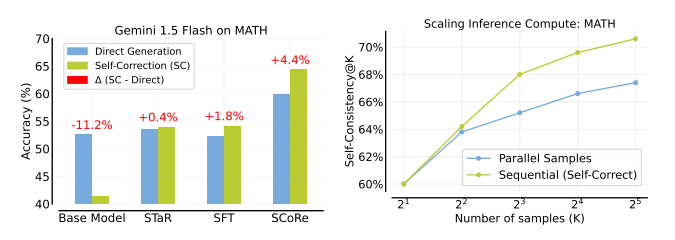
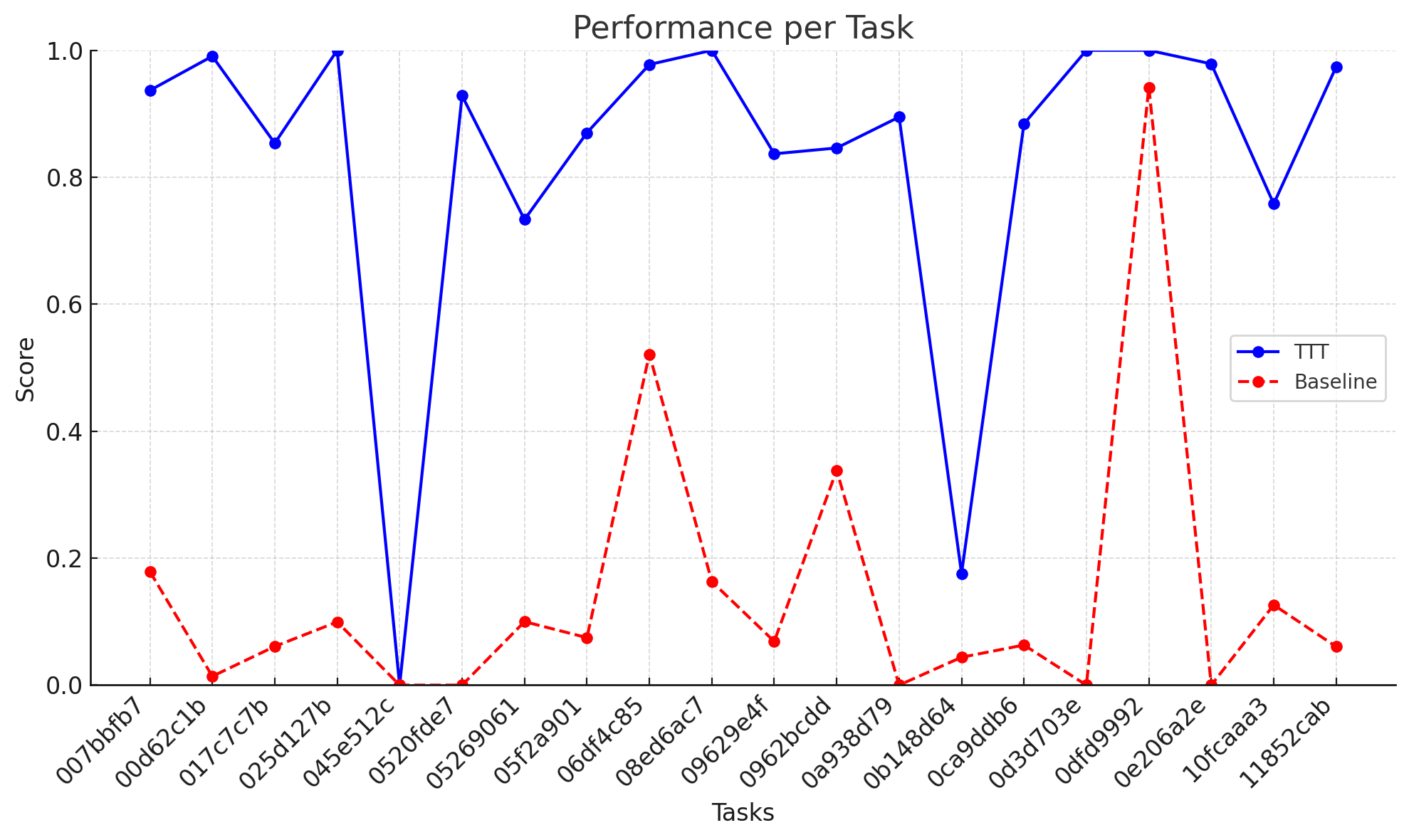
ARC Test-Time Training
Simplified test-time training for ARC-AGI abstract reasoning tasks. Fine-tunes per-task LoRA adapters on augmented training examples at inference time to boost puzzle-solving accuracy.
Happy to discuss any of these — feel free to reach out.